 ChatGPT Pro 俱乐部
ChatGPT Pro 俱乐部
Clawdbot 部署接入飞书(Lark):从插件到模型代理的完整踩坑指南
参考项目:
- 旧仓库(历史参考):https://github.com/lekuduo/clawdbot-lark-plugin
- 更名后的新仓库(推荐以此为准):https://github.com/lekuduo/moltbot-lark-plugin
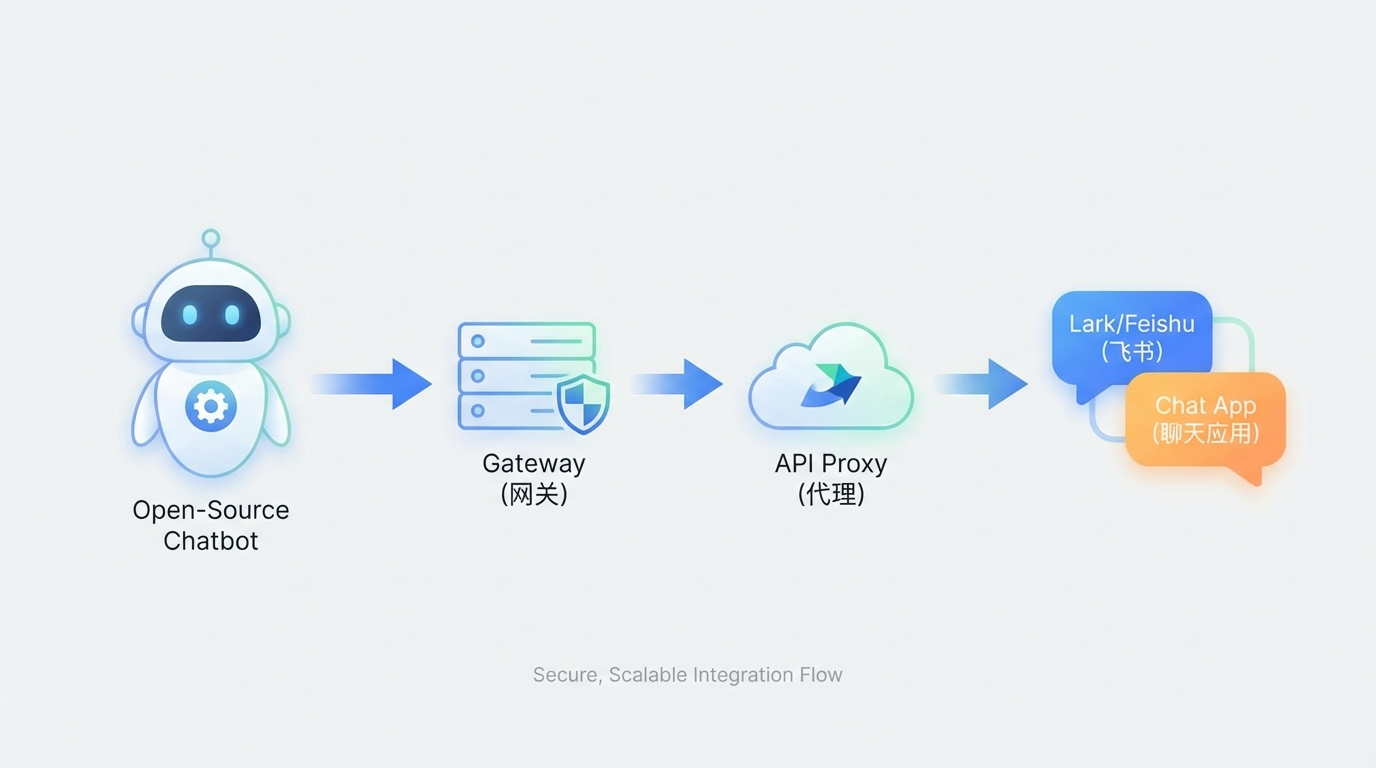
这篇文章记录一次把 Clawdbot 接入飞书(Lark) 的落地流程:包括插件选择、部署方式、以及在使用第三方 Claude API 代理(例如 CRS)时的配置与常见坑。
1. 选哪个飞书插件?clawdbot-lark-plugin vs moltbot-lark-plugin
lekuduo 最早提供的是 clawdbot-lark-plugin,后续项目更名并迁移到 moltbot-lark-plugin。
- `clawdbot-lark-plugin`:可作为历史实现参考
- `moltbot-lark-plugin`:更贴近当前生态(Moltbot / MoltHub),建议以它为主
因此:如果你现在要做新接入,优先看 moltbot-lark-plugin,旧仓库只用来对照。
2. 部署思路概览
整体链路通常是:
1. 飞书机器人(Lark Bot)负责接收/发送消息
2. Lark channel plugin 将消息接到 Clawdbot(或 Moltbot)
3. Clawdbot 负责:
- 对话/指令解析
- 调模型(Claude / OpenAI / Gemini / 代理)
- 调用工具(web_search/web_fetch 等)
- 回发消息到飞书
你需要准备的主要东西:
- 飞书开发者后台:创建应用/机器人、配置事件订阅与权限
- 服务器:部署 Clawdbot + Lark 插件(以及可能的反向代理/公网回调)
3. 使用第三方 Claude API 代理(如 CRS)的配置示例
如果你希望 Clawdbot 不直连官方 Claude,而是走第三方 Anthropic-compatible proxy(例如 CRS),通常需要在配置文件里:
- 把 `model` 指向你的代理 provider
- 在 `modelConfig`(或 providers 配置)里写明 `type/baseUrl/apiKey`
下面给一个示例(字段名以你当前的 Clawdbot/Moltbot 配置结构为准,思路是通的):
```json
{
"model": "crs/claude-opus-4-5-20251101",
"modelConfig": {
"crs": {
"type": "anthropic",
"baseUrl": "https://your-proxy-api.com/api",
"apiKey": "your-api-key"
}
}
}
```
说明:
- `baseUrl`:你的代理地址(通常会把 Anthropic 的 messages API 做成兼容层)
- `apiKey`:代理服务的 key
- `model`:指向代理命名空间下的目标模型
4. 常见坑:使用代理 API 时,工具调用可能报错
在一些代理方案下(尤其是只代理了“模型 API”,没代理 Clawdbot 的工具/搜索能力,或者网络策略限制),你可能会遇到:
- `web_search` / `web_fetch` 调用失败
- 或者工具链被代理侧的安全策略拦截
如果你确认短期内不需要这些工具,最直接的办法是 禁用相关工具(减少报错、提升稳定性)。
示例:
```json
{
"tools": {
"deny": ["web_search", "web_fetch"]
}
}
```
建议策略:
- 生产环境先追求“对话稳定 + 指令稳定”
- 工具能力(搜索/抓取)等稳定后再逐步打开
5. 建议的验证步骤(排障顺序)
1. 先验证飞书消息能进出:只做 echo/简单回复
2. 再验证 模型调用:固定 prompt,确认能稳定返回
3. 再验证 长文本/多轮对话:看看是否有超时/截断
4. 最后再打开 工具能力:web_search/web_fetch 等
只要按这个顺序,基本能把问题定位在:
- 飞书侧(权限/回调/签名)
- 插件侧(事件解析/路由)
- Clawdbot 侧(模型/工具配置)
- 代理侧(兼容性/限流/安全策略)
6. 参考链接
- Clawdbot Lark(飞书)旧插件:
- Moltbot Lark(飞书)新插件: